
Исследователи Microsoft анонсировали новую модель искусственного интеллекта (ИИ) для преобразования текста в речь под названием VALL-E, которая может точно имитировать голос любого человека при получении 3-х секундного звукового образца голоса. Этого вполне достаточно, чтобы VALL-E смог синтезировать звук.
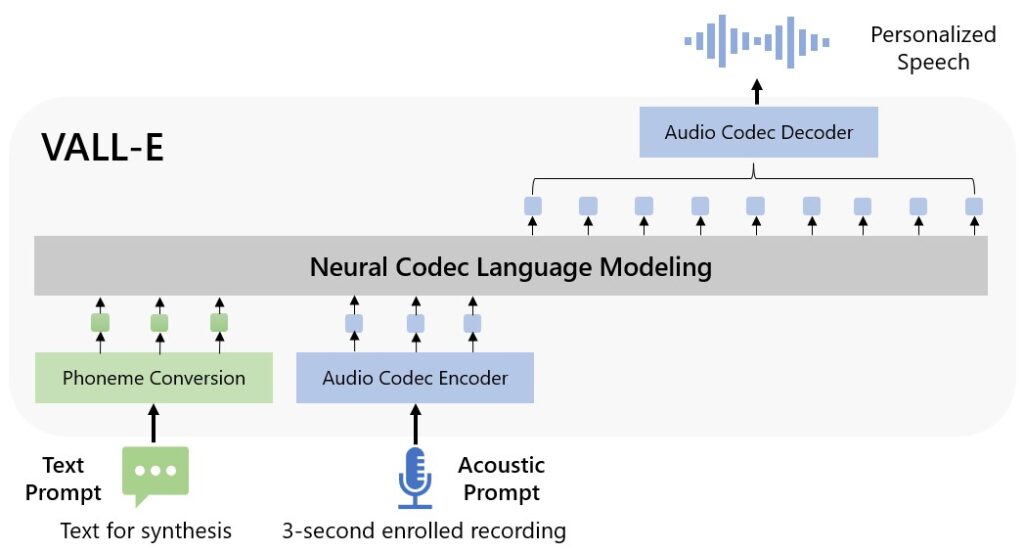
Microsoft называет VALL-E «языковой моделью нейронного кодека». Она основана на технологии под названием EnCodec, которую Meta анонсировала в октябре 2022 года. В отличие от других методов преобразования текста в речь, которые обычно синтезируют речь путем манипулирования формами сигналов, VALL-E генерирует дискретные коды аудиокодека из текстовых и звуковых подсказок.
Microsoft обучила VALL-E на аудиотеке LibriLight, собранной компанией Meta. Он содержит 60 000 часов англоязычной речи от более чем 7000 образцов голоса, в основном взятых из общедоступных аудиокниг LibriVox. Для получения хорошего результата VALL-E голос в трехсекундной выборке должен точно соответствовать голосу в обучающих данных.
Вы можете ознакомиться с результатами синтезированного голоса на специальном сайте аудио-примеров модели ИИ в действии.
Согласно заявлению Microsoft, VALL-E не будет распространятся в открытом доступе по соображениям безопасности, чтобы нейросетью не воспользовались мошенники.